[ASICs] [Chip Typen] [Chip Aufbau] [Entwicklung] [Schnittstellen] [Glossar]
[Buffer Types] [Interfaces] [Networks] [IEEE 802 Networks] [Data Lines] [Protocols] [Organazations]
[Line Codes] [Multiplexing] [Modulation] [Line Rates] [Encryption]
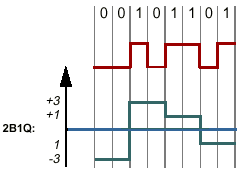 Line Codes
Line Codes
The following page gives a rough overview about line coding and data coding techniques. These describe how a certain data channel has access to a physical medium beside other data channels.
Line Coding Basics
Transmission of serial data over any distance, be it a twisted pair, fiber optic link, coaxial cable, etc., requires maintenance
of the data as it is transmitted through repeaters, echo chancellors and other electronically equipment. The data integrity must be maintained through data reconstruction, with proper timing, and retransmitted.
Line codes were created to facilitate this maintenance. In selecting a particular line coding scheme some considerations must be made, as not all line codes adequately provide the all important synchronization
between transmitter and receiver. Other considerations for line code selection are noise and interference levels, error detection and error checking, implementation requirements, and the available bandwidth.
Unipolar Coding
The most basic transmission code is unipolar or unbalanced coding. In this scheme each discrete
variable is transmitted with a different assigned level, 0V and for example +2.5V. But this holds a number of disadvantages:
- The average power is two times other bipolar codes
- The coded signal contains DC and low frequency components.
- When long strings of zeros are present, a DC or baseline wander occurs.
- This results in loss of timing and data because a receiver/repeater cannot optimally discriminate ones and zeros.
- Repeaters/receivers require a minimum pulse density for proper timing extraction. Long strings of ones or zeros contain no timing information and lead to timing jitter (when a clock recovery is used) and possible loss of synchronization.
- There is no provision for line error rate monitoring.
Bipolar Coding
With bipolar, or also called balanced coding, the same data may be transmitted more efficiently
achieving the same error distance with half the power. This coding is often referred to as Non-Return to Zero (NRZ) coding as the signal level is maintained for the duration of the signal interval. Although
bipolar coding is more efficient than unipolar, it still lacks provisions for line error monitoring, and is susceptible to DC wander and timing jitter. This coding scheme provides a number of features which:
- Eliminate DC Wander
- Minimize Timing Jitter
- Provide for Line Error Monitoring
This is accomplished by introducing controlled redundancy in the code through extra coding levels.
Line Coding Techniques
2B1Q 2 Binary 1 Quaternity
4B5B 4 Bit / 5 Bit
8B10B 8 Bit / 10 Bit
AMI Alternate Mark Inversion
B6ZS Bipolar with 6 Zero Substitution
B8ZS Bipolar with 8 Zero Substitution
BAMI Bipolar-Alternate Mark Inversion
Differential Manchester Encoding
HDB3 High Density Bipolar 3
Manchester Encoding
NRZ Nonreturn to Zero
NRZI Nonreturn to Zero Inverted
Pseudoternary
Data Coding Techniques
CRC Cyclic Reduncancy Check
FEC Forward Error Correction (different algorithms)
Convolutional Codig
![]()
2B1Q
The 2B1Q (two binary, one quaternary) line encoding scheme was intended to be used by the ISDN
DSL and SDSL applications. This code is a four-level line code in which two binary bits (2B) represent one quaternary symbol (1Q). The 2B1Q line coding was seen as a major enhancement over the original
T1 line coding, because 2B1Q encoded two bits per signal change instead of just one per change. (see picture on the top of this page).
4B5B 4 Bit / 5 Bit
4B5B uses 5 bit signals for each 4 data bits. The 5 bit sequences are chosen so that there are never
more than 3 consecutive zeros in the output stream. When used with NRZI, will have at least 2 signal transitions in every 5 bits.
8B10B 8 Bit / 10 Bit
8B10B coding is used in interfaces as PCI Express, InfiniBand, XAUI, Fibre Channel, DVB-ASI, and
others. In this applications B10B transmission code provides the following functions:
- Improves transmission characteristics
- Enables bit- level clock recovery
- Improves error detection
- Separates data symbols from control symbols
- Derives bit and word synchronization
The data bytes are encoded into 10-bit data characters resulting into 1024 possible characters. 2x256=512 are reserved for the data byte transfers. One character representative has more 1's, the
other has more 0's and are selected according to the current disparity (see below). 12 special characters are defined for special signaling. The rest of the 1024-512-12 are not allowed for transmission and
indicate transmission errors or unsynchronized status once they are received at the destination. Ordered sets are flexible building blocks which may be used for in-band and or out-of-band protocol functions.
8B10B code recognizes the idea of a Running Disparity (the difference between the number of 1s and 0s transmitted). The sender keeps the running disparity around zero, the receiver checks the data
stream according to this rules and is thus able to detect some transmission errors. Other neighboring coding schemes like 64B66B are available and are used in certain applications..
AMI Alternate Mark Inversion
Used in North American T1 (1.544MHz) and T1C (3.152MHz) lines.
B6ZS Bipolar with 6 Zero Substitution
Used in North American T2 (6.3212MHz) lines.
B8ZS Bipolar with 8 Zero Substitution
B8ZS is used commonly in North American T1 (1.544MHz) and T1C (3.152MHz) carriers. For every
string of 8 zeros, bipolar code is substituted according to the following rules:
- If the immediate preceding pulse is of (-) polarity, then code each group of 8 zeros as 000-+0+-.
- If the immediate preceding pulse is of (z) polarity, then code each group of 8 zeros as 000+-0-+.
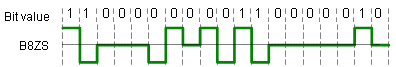 |
BAMI Bipolar-Alternate Mark Inversion
BAMI uses 3 signal levels: +V, 0, -V
0 = no signal (0 voltage)
1 = alternating +V and -V
BAMI has no DC component becaus of regularly alternating between +V and -V. Thus it is also able to detect some bit errors between consecutive +V or -V. The problems are a loss of synchronization
during long string of 0 bits and the inefficient use of bandwidth. With 3 signal levels BMI you could transmit log2(3)= 1.58 bits of information.
Differential Manchester Encoding
Mid-bit transition is used only for clocking
0 = transition at beginning of bit period (low-to-high or high-to-low, depending on previous output level)
1 = no transition at beginning of bit period
This coding is used in IEEE 802.5 (Token Ring) at 4Mbps and 16Mbps. It has the same properties as Manchester encoding, but a better signal detection and clocking in presence of noise. Still there is the
inefficient use of bandwidth.
HDB3 High Density Bipolar 3
Another coding scheme is HDB3, high density bipolar 3, used primarily in Europe for 2.048MHz (E1)
carriers. This code is similar to BNZS in that it substitutes bipolar code for 4 consecutive zeros according to the following rules:
- If the polarity of the immediate preceding pulse is (-) and there have been an odd (even) number of logic 1 pulses since the last substitution, each group of 4 consecutive zeros is coded as 000-(+00+).
- If the polarity of the immediate preceding pulse is (+) then the substitution is 000+(-00-) for odd (even) number of logic 1 pulses since the last substitution.

Manchester Encoding
Always transition in middle of bit period:
0 = low-to-high transition
1 = high-to-low transition
Transition at beginning of bit period when necessary used for 10Mbps ethernet over coax and twisted pair Manchester encoding is good for clock and signal recovery. There is no DC component, but it has
an inefficient use of bandwidth (10Mbps ethernet uses a 20Mbps signaling rate). It has a data-dependent high frequency component.
NRZ Nonreturn to Zero
1 = signal on
0 = signal off (no signal)
NRZ is used on low speed links, such as serial ports. Its problems are lack of clock recovery during long string of 0 or 1 bits and it has a DC component resulting in baseline wander during long strings of 0 or 1 bits.
NRZI Nonreturn to Zero Inverted
1 = change of signal level (on-off or off-on)
0 = no change of signal level
NRZI is a differential encoding used in 4B/5B on fast ethernet. It fixes problems in clocking during long strings of 1 bits. The problems are the DC component and the lack of clock recovery during long string of 0 bits.
Pseudoternary
Pseudoternary has the same behavior as Bipolar-AMI except it reverses signaling:
1 = no signal (0 voltage)
0 = alternating +V and -V
![]()
CRC Cyclic Redundancy Check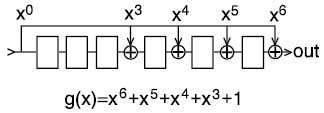
CRC is an easy scheme to generate a checksum from a given data block or serial bit stream. CRC is based on a loop-back shift register with several XORed taps. The specification of a certain CRC-n algorithm to
calculate the n-bit checksum is based on a serial bit stream, but it can be transformed to any input data width enabling the calculation of several bit shifts within one clock cycle. An example is
the 4 bytes of an ATM header in 4 clock cycles to calculate the 8 bit Header Error Correction (HEC) field as the 5th header byte.
Following CRC standard polynoms are in use in different applications:
|
|||||||||||||||||||||||||||||||||||||||
FEC Forward Error Correction
FEC is a method for controlling errors in systems with a one-way communication. FEC sends extra
information along with the data, which can be used by the receiver to check and correct the data without the need for retransmitting the wrong data packets. Secondly FEC is to improve the capacity of a
channel by adding some carefully designed redundant information to the data being transmitted through the channel (channel coding). Convolutional coding and block coding are the two major forms of
channel coding. Convolutional codes operate on serial data, one or a few bits at a time. Block codes operate on relatively large (typically, up to a couple of hundred bytes) message blocks. There are a
variety of useful convolutional and block codes, and a variety of algorithms for decoding the received coded information sequences to recover the original data.
Related references to this error control approach include "Trellis Coding", "Viterbi Decoding", and "Turbo Coding".
FEC is often based upon CRC (Cyclic Redundancy Check) schemes which can be generated with a shift loop-backed register (http://ralf-eisenreich.de/crc___fcs.111.0.html).
Convolutional Coding
Convolutional encoding with Viterbi decoding is a FEC technique that is particularly suited to a channel
in which the transmitted signal is corrupted mainly by additive white gaussian noise (AWGN). You can think of AWGN as noise whose voltage distribution over time has characteristics that can be described
using a Gaussian, or normal, statistical distribution. This voltage distribution has zero mean and a standard deviation that is a function of the signal-to-noise ratio (SNR) of the received signal. 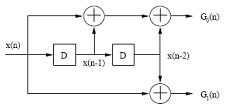
Convolutional codes are usually described using two parameters code rate and constraint length. The code rate k/n, is expressed as a ratio of the number of bits into the convolutional encoder (k) to the number of channel symbols output by the convolutional encoder (n) in a given encoder cycle. The constraint length parameter K, denotes the "length" of the convolutional encoder, i.e. how many k-bit stages are available to feed the combinatorial logic that produces the output symbols. Closely related to K is the parameter m, which indicates how many encoder cycles an input bit is retained and used for encoding after it first appears at the input to the convolutional encoder. The m parameter can be thought of as the memory length of the encoder.
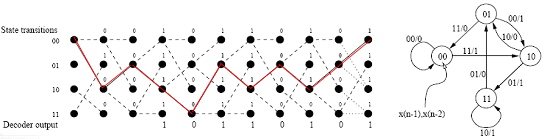 |
Viterbi decoding has the advantage that it has a fixed decoding time. It is well suited to hardware decoder implementation. But its computational requirements of Trellis path analysis (picture) grow exponentially as a function of the constraint length, so it is usually limited in practice to constraint lengths of K = 9 or less. For years, convolutional coding with Viterbi decoding has been the predominant FEC technique used in space communications.
|
The other type of convolutional coding is sequential decoding. This type has the advantage that it can perform very well with long-constraint-length convolutional codes, but it has a variable decoding time
![]() (last update: September 2005)
(last update: September 2005)
[Home] [ASICs] [Selbstmanagement] [Inselmeer] [Spiele]
[Ich über mich] [Links] [SiteMap] [Disclaimer]